
언어모델(Language Model)
문장이 얼마나 자연스러운지를 확률적으로 계산 및 예측하는 모델
컴퓨터는 사람의 말을 곧바로 이해할 수 없기 때문에 자연어 처리(NLP)라는 과정이 필요함
크게 통계학적 언어 모델과 딥러닝 기반의 언어 모델이 있으며, 최근에는 딥러닝 중에서도 인공신경망을 가장 많이 이용
대규모 언어모델(LLM; Large Language Model)
모델 사이즈를 키워 대용량의 텍스트 데이터를 학습시킨 성능을 극대화한 언어모델
기존의 머신러닝 모델에 비해 파라미터 수가 아주 많음
파라미터(parameter, 매개변수)
머신러닝에서 모델이 스스로 내부에서 결정하는 변수 또는 가중치
뉴런 사이에서 정보를 전달하는 시냅스와 같은 역할
GPT-3 모델에는 약 1750억 개의 파라미터가 사용됨

백본(backbone)
- 하나의 초대규모 모델, 또 다른 모델의 뼈대 역할
- 만들어진 오픈소스 사전학습 모델을 미세 조정(fine tuning)하여 목적에 맞게 사용
- 국내에서도 BERT를 활용하여 한국어에 특화된 KorBERT 모델을 한국전자통신연구원이 개발
- GPT(Open AI), BERT(구글), RoBERTa(페이스북), Turing-NLG(마이크로소프트) 등
멀티 모달 인공 지능 (Multimodal AI)
- 여러 개의 데이터 형식을 가지고 수행하는 AI
- 다양한 데이터 종류 (텍스트, 음성, 이미지, 수치형 데이터)와 스마트 처리 알고리즘을 결합하여 서로의 관계성 학습
ex) 이미지로 텍스트 검색, 텍스트에서 이미지를 검색, 이미지와 텍스트를 같이 이해하는 멀티모달 검색, 이미지를 보고 텍스트를 생성, 텍스트를 기반으로 이미지를 생성

↔ 유니모달
- 멀티모달 이전의 AI 모델
- 한 가지 정보만 해석
- ChatGPT 등
멀티모달 vs 멀티모델
멀티모델
input data의 종류가 1가지면서 여러개의 모델을 거치는 방식

멀티모달
input data의 종류가 2가지 이상이며, 모델은 1개가 될수도 있고 2개가 될수도 있는 방식

멀티 모달의 종류
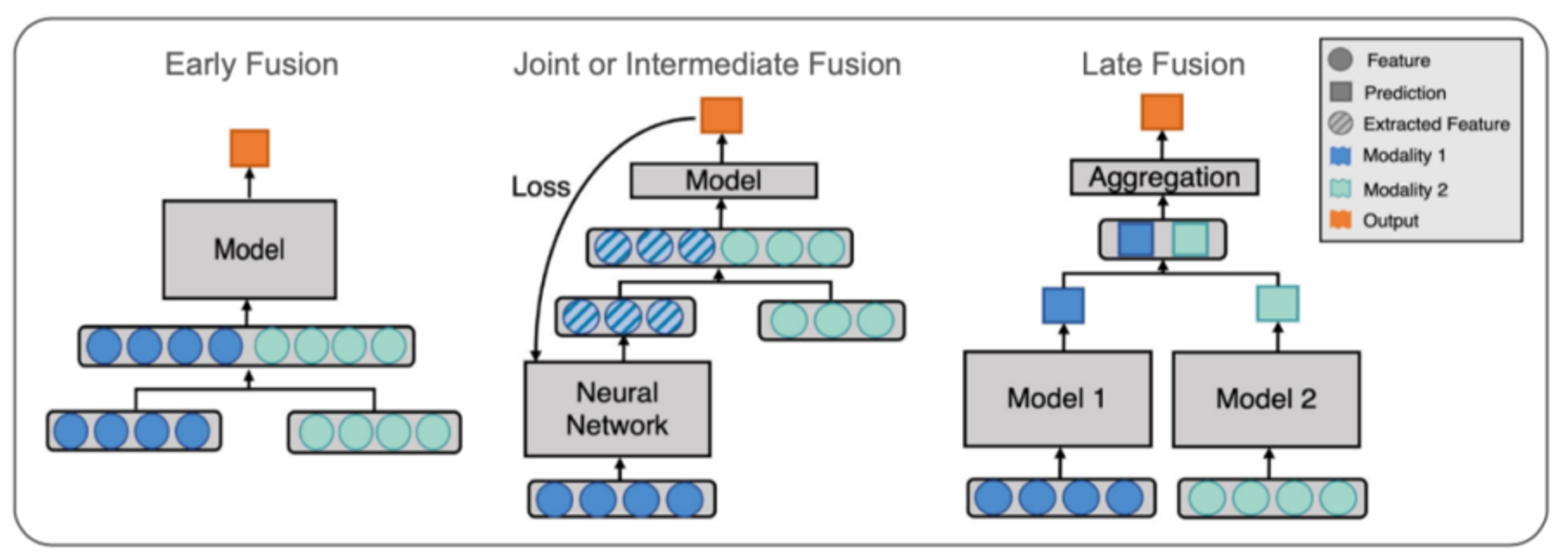
Early Fusion
- 종류가 다른 두가지 데이터를 하나의 데이터로 먼저 합친 이후 모델 학습
- 형식이 다른 두 데이터를 합치기 위해서 다양한 데이터가 변환
- 원시데이터를 그대로 융합해도 되고, 전처리를 한 이후에 융합해도 상관없음
Late Fusion
- 종류가 다른 두가지 데이터를 각각 다른 모델에 학습시킨 이후 나온 결과를 융합
- 기존의 앙상블모델이 작동하는 방식과 비슷
Joint or Intermediate Fusion
- 두개의 모달리티 데이터를 동시에 학습시키지 않고 내가 원하는 모델의 깊이에서 모달리티를 병합
- 하나의 모달리티로 모델학습을 진행하던 중 모델학습의 마지막 레이어 전 다른 모달리티와 융합 (end-to-end learning)

과정
(a) 서로 다른 모달을 가진 3개의 데이터(RGB:이미지.png / skeleton:좌표.json / depth maps:거리.tiff)가
(b) 모델 레이어층으로 들어가 특징 추출(features extraction)을 수행하고
(c) 그 중 데이터 특징을 가진 특징만 추출하여 3개 데이터의 특징을 하나의 데이터로 융합
(d) 융합된 하나의 데이터가 마지막 분류모델로 들어가 결과를 출력
멀티 모달 사용 예시
- 멀티모달 중 텍스트 데이터와 함께 사용하는 것이 가장 활발함
- 해외에는 대규모 멀티모달 학습 데이터 셋들이 공개되어 있지만, 아직 대규모로 한국어 멀티모달 모델을 학습할 수 있는 데이터는 공개되어 있지 않음
이미지 + 텍스트(검색어)

이미지+오디오


cue:
한국어 특화 검색 AI 서비스
네이버에서 가지고 있는 데이터 기반으로 정보 제공

네이버
- 네이버 내의 이미지-텍스트 페어 데이터를 효율적으로 수집하는 파이프라인 설계
- 고품질의 데이터 구축을 위해 이미지와 텍스트를 고려한 정제 과정이 중요
주요 과정

- 중복 처리를 거친 네이버 내 이미지를 수집 후, 이미지 사이즈, 비율, 화이트 픽셀 비율 등의 기준으로 필터링
- 네이버 내 문서 관련 텍스트 및 쿼리를 필터링 기준에 따라 수집
- 이미지 중복 처리 시 생성된 Image_hash 값과 문서 내 이미지 및 텍스트 정보, 클릭 정보를 활용
- 이미지와 텍스트를 병합한 후, 추가 필터링을 위한 워터마크 탐지, OCR, Image-text score 계산 등의 GPU가 필요한 로직을 병렬 처리
- 데이터셋을 효율적으로 학습하기 위해 Webdataset 포맷으로 변환 및 압축 (예: train-000.tar)
네이버의 멀티모달 모델
패션 상품 속성 검색 모델


- 트랜스포머(Transformer) 기반의 인코더 모델 구조에서 상품 이미지를 이미지 인코더에 입력
- 상품의 카테고리 및 속성 정보를 텍스트 인코더에 입력
- 이미지 임베딩과 카테고리 임베딩을 더 한 값과 속성 임베딩에 대해서 Contrastive 학습 진행
- 결과적으로 이미지와 카테고리 정보를 입력으로 사용하면 상품 속성 정보를 검색할 수 있는 이미지 기반 상품 속성 검색 모델 생성
Contrastive 학습
서로 다른 두 데이터의 임베딩 벡터를 비교하면서 비슷한 데이터끼리는 가까워지도록(낮은 거리), 서로 다른 데이터끼리는 멀어지도록(높은 거리) 학습
이미지와 텍스트 간의 연관성을 더 잘 이해할 수 있는 모델
ex) 같은 상품에 대한 이미지와 텍스트 쌍을 positive pair로, 다른 상품에 대한 이미지와 텍스트 쌍을 negative pair로 설정
범용 태스크를 위한 멀티모달 VLM(Vision Language Model)
- 상품 속성 검색 뿐만 아니라 더 다양한 도메인과 태스크에 멀티모달 모델을 활용하기 위해 구글의 CoCa(Contrastive Captioners are Image-Text Foundation Models) 논문을 참고하여 네이버만의 범용 VLM(Visual Language Model) 모델을 구축
- 이 모델은 이미지 인코더와 텍스트 인코더를 사용하여 패션 상품 속성 검색 모델처럼 ITC(Image-Text Contrastive)학습을 하면서 동시에, 이미지에 대한 텍스트 생성에 대해서도 같이 학습
- 따라서 이미지-텍스트 검색 뿐만 아니라 이미지에서 텍스트를 생성하는 태스크에서도 모두 좋은 성능을 보여줌
다중언어(Multi-lingual) 텍스트 인코더를 적용한 한국어 Text-to-Image 생성
- Stable Diffusion 모델이 오픈소스로 공개되면서 텍스트 기반의 다양한 이미지 생성 및 편집 작업이 가능해짐
- 하지만 해당 모델에서 텍스트 조건을 넣는 텍스트 인코더 역시 영어 데이터셋으로 학습되었기 때문에 한글을 입력하면 엉뚱한 이미지가 생성되는 한계
- 따라서 Stable Diffusion 모델 내 한글을 처리할 수 있는 텍스트 인코더를 새롭게 학습


- 한글 텍스트를 처리할 수 있는 텍스트 인코더를 학습하기 위해 기존의 영어 텍스트 인코더를 활용한 Knowledge Distillation 방식을 사용
- 한영 페어의 번역 데이터를 이용하여 기존의 영어 텍스트 인코더를 고정시킨 상태에서 임베딩을 계산
- 새로운 다중언어 텍스트 인코더가 그것에 따라갈 수 있게 학습
- 한영 모두 같은 잠재 공간 상에서 표현이 가능
그 결과 기존에 한글로 입력을 했을 때와 비교하여 훨씬 관련성이 높은 이미지가 생성됨
다중언어 모델이기 때문에 한글뿐만 아니라 영어 프롬프트에서도 잘 동작됨

멀티모달 문서 검색 서비스(MDS) 적용 사례
스마트 썸네일
구축한 VLM 모델을 활용해 유저의 텍스트 쿼리와 이미지 사이의 연관도 점수를 기반으로 문서 내의 여러 이미지들 사이에서 텍스트 쿼리와 관련도가 높은 순으로 랭킹을 매긴 후, 썸네일로써 좋은이미지를 선택하는 기술
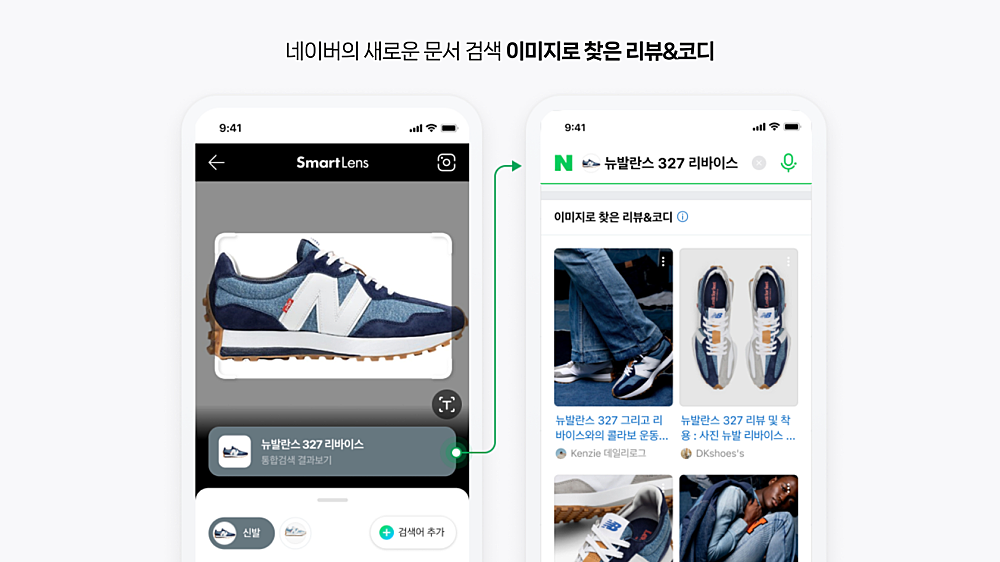

멀티모달 기반 패션 상품 검색
유저의 이미지 쿼리에 대해 여러 문서 내 유사한 상품을 검색

- 먼저, 쿼리 이미지가 입력되면 타겟 카테고리(예: 신발)에 해당하는 부분을 Object Detector로 찾아내어 이미지를 해당부분만 잘라내기(Crop)합니다.
- 이미지 피처를 추출하고 검색할 때는 앞서 구축한 네이버의 다양한 VLM 모델을 사용합니다.
- 각 VLM 모델마다 추출되는 특징이 달랐기 때문에 여러 검색 후보군을 선정하는 데 도움이 되었습니다.
- 마지막으로, VLM 기반의 Image-text Reranking을 통해 최종 상품 랭킹을 결정합니다. 이렇게 간단한 구조로 성능이 우수하며, 하였습니다.
신발과 달리 상품명이 불명확한 의류의 경우
-> 의류 색상과 패턴과 같은 요소를 문서 검색에 활용하기 위해 추가 태깅을 진행

그에 따라 발생한 발생한 데이터 불균형 문제를 해결하기 위해 Text-to-image 생성 모델을 사용
데이터 증강이 진행되며 색상 및 패턴 분류 모델의 성능이 개선

제미나이(Gemini) AI
https://deepmind.google/technologies/gemini/#introduction
- 구글과 딥마인드가 개발한 멀티모달 생성형 인공지능 모델
- 텍스트 뿐만 아니라 오디오, 이미지, 비디오와 같은 다양한 입출력을 지원
- GPT와 같은 텍스트 기반의 언어 모델과는 달리 처음부터 멀티 모달로 개발
시연 영상
https://www.youtube.com/watch?v=UIZAiXYceBI&t=225s
ChatGPT-4
ChatGPT 와 GPT-4의 차이점
AI 모델의 파라미터 수가 커지며, 모델의 최대 입력 토큰 수 기존 4,096개에서 32,768개로 증가
멀티모달 기능 추가
시각화
LLM Visualization
bbycroft.net
https://channeltech.naver.com/contentDetail/22
https://channeltech.naver.com/contentDetail/25
https://blog.kubwa.co.kr/멀티모달-multi-modal-ai-총정리-예제-실습-코드-0982b35a7077